Surprise : notre ADN renferme une deuxième couche d’information
Une équipe de physiciens théoriciens de Leiden (aux Pays-Bas) vient de démontrer que notre ADN cache en réalité une deuxième couche d’information, en sus de la séquence du génome bien connue (les fameuses lettres GATC). Un soupçon que la communauté scientifique entretenait depuis 1980, mais dont l’intérêt échappait jusqu’ici à leur sagacité.
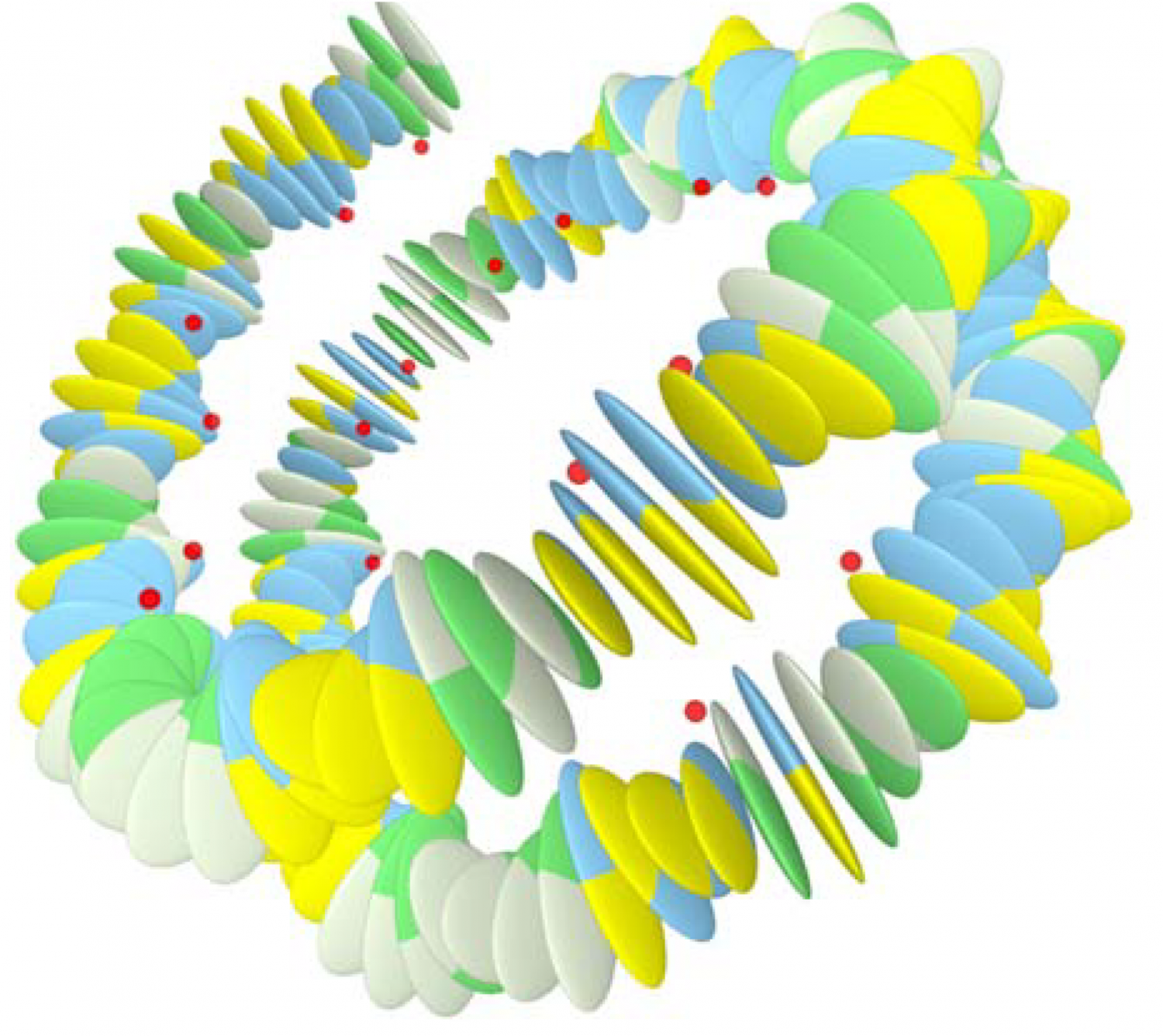
(Crédit illustration : Leiden Institute of Physics)
Tout le monde a eu des cours de bio et vu Gattaca, vous savez donc que notre ADN est composé de séquences des lettres G, A, T et C et que c’est l’enchaînement de ces lettres qui va permettre l’encodage des protéines. Ça, on le sait depuis les débuts de la génétique moderne.
En revanche, ce qu’on ne savait pas (ou plutôt, on le savait mais on ne savait pas trop comment ni pourquoi), c’est que notre ADN comporte également une deuxième « couche » d’information. En gros, dans nos cellules, on trouve deux mètres de molécules d’ADN, confortablement enroulées pour tenir dans cet espace restreint (ce qu’on appelle la condensation de l’ADN).
Ce que la team de Leiden a mis en lumière, grâce à des simulations informatiques, c’est que la manière dont ces molécules sont enroulées détermine également la quantité de protéines qu’elles vont générer.
Pour schématiser : outre la séquence du génome, les contraintes mécaniques liées à cet « enroulement » vont également favoriser l’une ou l’autre partie de la séquence d’ADN à être « lue », et donc influencer la fréquence de production des différentes protéines.
C’est une découverte plutôt maousse pour la biologie, et la science en général. Les implications d’une meilleure lecture de l’ADN sont une des clés vers de meilleurs outils pour les généticiens. Des outils qui leur permettront de mieux comprendre l’importance de l’ADN dans l’évolution, de mieux lutter contre le cancer et autres maladies, mais aussi d’améliorer biologiquement l’être humain. Avec toutes les implications éthiques qu’on peut imaginer…
Pour ceux qui voudraient approfondir la lecture, le papier intégral est disponible ici.
Merci à Docteur Saucisse et St Yfrit pour les explications.